关于HBase
Hadoop
- Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。
- Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中。
- Hadoop不是一个技术,而是一个项目,的核心是分布式文件系统HDFS(Hadoop Distributed File System)和MapReduce,HDFS解决了存储问题,MapReduce解决了处理问题。
本文不重点介绍关于Hadoop的历史与架构,有关于Hadoop的前世今生和项目介绍,可以参考一下内容:
有关于hadoop的安装说明可以参考以下两篇文章:
- https://blog.csdn.net/hliq5399/article/details/78193113/
- http://dblab.xmu.edu.cn/blog/install-hadoop/
本团队发布了docker镜像hadoop-dev,其上配置了hadoop 2.6版本,供开发测试使用。
HBase
HBase是Hadoop项目的一部分,是一个可扩展的、分布式的数据库,可以支持海量的半结构化的数据。HBase以Google的Bigtable为模型,简历在Hadoop之上,正成为需要快速随机访问大量数据的应用程序越来越受欢迎的数据库选择。
HBase与传统的关系数据库(如MySQL,PostgreSQL,Oracle等)非常不同。因此需要了解它的结构,已决定如何设计架构以及为使用它的应用程序提供的功能。为了实现可扩展性和灵活的模式,HBase权衡了其中一些功能,这也使得HBase的数据结构设计和关系数据库系统相比,有一些差异。
尽管我们最终可能会通过一些方式,不直接进行HBase的结构设计(如:Phoenix, Flink, Spark等),但是了解HBase的结构仍然对我们理解数据结构和开发过程非常有帮助,也是非常重要的。
基本结构
访问一个HBase中的数据需要对数据进行定位。HBase采用的是一个稀疏的、分布式的、多维有序的数据存储方式。每一个数据存储在一个Cell中,要确定一个Cell的位置需要以下元素:
- Table
- Row key
- Column key
在一个Cell内,还可以通过Timestamp存储值的不同版本。
注: 尽管很多书籍和文章中都有关于上述元素的标准翻译,但是本文中尽量直接使用这次名词的英文形式,以避免在开发过程中需要过多的语言转换。
定义
Table
HBase将数据组织在tables中,tables的名字必须是字符串,对于字符串的要求,是必须是符合文件路径名称要求的。这也是由于HBase的数据时存储在HDFS上的原因。
HBase允许表名上带有namespace,例如:表名可设计为b”akimimi:orders”,akimimi即为namespace。HBase的一些系统数据存储在namespace为hbase的表中,如果不指定namespace,则namespace为default。
Row
在一个table内,数据存储以行为组织单位每个行具有一个唯一的键值,即row key。row key的没有特定的数据类型,它总是被视为一个byte数组。
注: HBase并不限定数据类型,所有的数据都是以byte数组来存储和访问的。
row key是在HBase中检索数据的主要数据,因此,使用什么数据作为一个表的row key是设计数据结构时首先要考虑。
Column
在HBase中,Column由Column Family和Column Quanlifier来组成。
需要注意的是同一个Column Family的数据具有相同的存储属性。并且在存储时,这些数据也是保存在一起的。因此,Column Family需要在创建表格时就确定,一般情况下Column Family不应该被频繁改动。每次改动Column Family的过程,都可能造成数据存储的重新组织。
所有行的Column Family是一致的,不管实际上是否有这些数据,或者Column Quanlifier是否一致。
Column Family的名称只能是字符串,并且和Table名称要求一致。
Column Quanlifier也可以简称为column,是在一个Family内的索引,这个索引键值不需要在创建表的时候设定,可以随着数据写入,也不需要保证行间的一致性。column的键值数据类型和row key相同,也是byte数组。
Cell
通过row key,column family,column qualifier的组合可以确定一个cell。数据保存在cell中,数据没有类型,全部都是byte数组。
Timestamp
一个cell中可以保存多个版本的数据值,版本通过timestamp来确定,在写入一个数据时,默认情况下timestamp就是当前时间。在读取数据时,默认情况下,读取的是最新的timestamp的数据。当然,也可以通过指定timestamp来写入不同的timestamp,或者读取历史版本。
一个cell保存多少个版本,是Column Family的属性决定的,默认情况下是3个。
数据格式
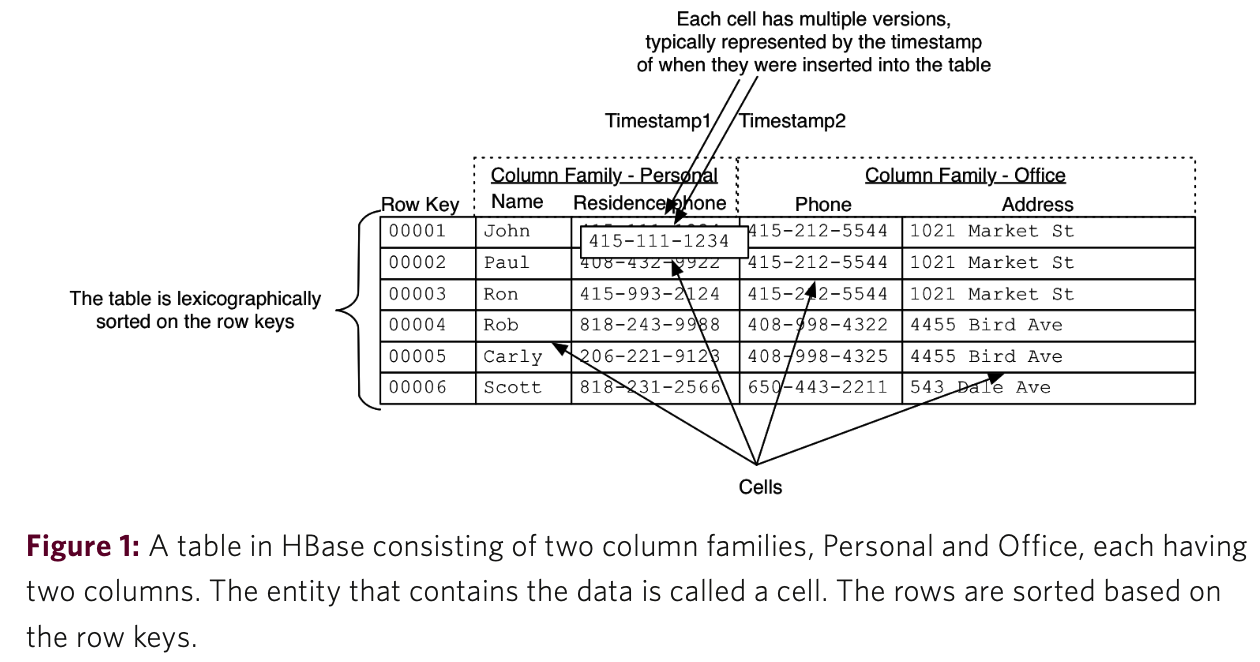
上图为HBase的数据结构图,由此可见,要准确读取一个数据,需要指定他在表内的:row key, column family, column qualifier, timestamp。
这些概念也体现在HBase的API接口上,主要包括:put, get, scan。
设计规范
基于HBase的存储结构,在设计数据结构时应考虑一下问题
- row key要保存什么数据?它应该保存成什么结构?
- 表格中应该有多少column family
- 什么样的数据,应该装入什么样的column family
- 每个column family中有多少个column
- column 的名字叫什么?虽然这不是必须要在创建表时指定的,但是仍会在读写数据时使用
- cell中的数据是什么样的
- 需要保存多少个版本
row key是设计表结构时最重要的元素,在设计表时应注意以下规则:
- 表格的索引只与row key有关
- 表格的存储时按照row key有序存储的,在底层,不同的region(HDFS结构)保存了一部分的row key,并且由row key的起始和终止元素标记。
- 所有储存在HBase中的数据都是byte数组,没有类型
- 原子化只在行内的级别才有,在行间是没有的,不能保证行间的原子化操作
- 在设计表时就应该确定好column family,并且名称应该尽可能短,这样可以节约数据在网络上的传输量
- column qualifier是动态的,可在数据读写时确定,甚至可以考虑用column qualifier来存储数据
使用HBase
阿里云的HBase服务
通过阿里云的HBase服务,我们可以直接获得一个搭建好的HBase Server,省略了自建Hadoop和HBase的过程。
Hadoop和HBase的搭建过程并不复杂,建议有兴趣的读者可以尝试在本地自行搭建Hadoop和HBase(Hadoop可以以伪分布式形式运行在单机上),以了解HBase的底层机制。Hadoop的搭建教程在上文中已经提供,HBase的搭建教程参考HBase搭建实验。
HBase Shell
官方提供了HBase Shell,可访问官方的下载链接,最高版本是2.3.0。
对于阿里云的HBase,阿里云也提供了一个HBase Shell,版本是HBase 2.0.0,是基于阿里云的HBase服务版本提供的。
两个Shell包都可以正常使用。如果不是本地HBase服务,使用Shell时先修改conf/hbase-site.xml,加入以下配置:
<property>
<name>hbase.zookeeper.quorum</name>
<value>zk1:2181,zk2:2181</value>
</property>
其中的zk1、zk2为HBase的zk链接地址。如果使用的是阿里云的HBase服务,那么需要将zk的地址填写为zk链接的外网地址。
HBase Shell命令
有关HBase Shell的全部命令请参考hbase shell commands
- 与表格结构有关的命令重点看:list/create/alter/describe
- 与数据读写有关的命令重点看:scan/get/put/delete/incr
- 与表操作有关的命令重点看:enable/disable/drop
Docker
不论是尝试HBase Shell还是后面会讲到的python开发,都可以直接在本机环境中进行。项目团队还是提供了一个名为akimimi/hadoop-dev的开发环境,截至本文撰写时版本为0.1.2。其中已经配置好了hadoop 2.7.7/JDK 1.8/Python3.7环境(以及一个virtualenv的例子并按照附录C配置了阿里云pip数据源),并提供了两个版本的HBase Shell。
开发
Python连接Hbase
Hadoop和HBase都是基于Java开发的,但是apache也提供了其他语言的API接口,详情可以参考:http://thrift.apache.org/
本文介绍两种Python连接HBase的方法,分别是通过官方的Thrift库以及第三方Happybase库。需要说明的是,阿里云提供的Thrift链接方式,只支持内网链接,如果在本地,则不能直接链接。可以通过阿里云的测试环境配置VPN,在开发调试时链接VPN以获得内网环境。有关VPN配置和操作说明参见附件A。
本文中所涉及的Python版本均为3.7版本,没有对低版本Python进行测试。建议在开发过程中,均使用virtualenv来保证Python的版本的正确性。有关于virtualenv的使用,参见附件B。
Thrift
apache官方提供了Thrift库,需要在HBase服务中添加,如果要本地的HBase服务支持Thrift请参照官方文档;阿里云的HBase已经支持了Thrift,可以直接使用。
首先,需要使用pip安装thrift和hbase-thrift库
pip install thrift hbase-thrift
安装成功后,我们的测试代码如下:
from thrift.transport import TSocket,TTransport
from thrift.protocol import TBinaryProtocol
from hbase import Hbase
socket = TSocket.TSocket('hb-2zebh40t9h0u54rtr-001.hbase.rds.aliyuncs.com', 9099)
socket.setTimeout(5000)
transport = TTransport.TBufferedTransport(socket)
protocol = TBinaryProtocol.TBinaryProtocol(transport)
client = Hbase.Client(protocol)
socket.open()
print(client.getTableNames()) # 获取当前所有的表名
执行代码时,可能会遇到以下提示:
Traceback (most recent call last):
File "hbase_thrift.py", line 3, in <module>
from hbase import Hbase
File "/usr/local/lib/python3.7/dist-packages/hbase/Hbase.py", line 2066
except IOError, io:
^
SyntaxError: invalid syntax
这是因为hbase_thrift的包是为Python2提供的,在Python3中对except的语法做了改动,应写为except IOError as io。HBase.py和ttypes.py两个文件都有一些在引用、异常处理、迭代循环方面的语法不兼容性问题。如果有兴趣,可以尝试去直接修改提示错误的HBase文件,直到调试成功。
本文也提供了修改后的文件,可以直接覆盖语法错误提示中的文件。参见:https://github.com/akimimi/hbase-thrift-python3
修正问题后,可得到以下结果:
['AUTO_DEMOS', 'AUTO_DEMOS_PRICE_DATE_SALE_IDX', 'AUTO_DEMOS_PRICE_NEW_SALE_IDX', 'AUTO_DEMOS_PRICE_REGISTER_SALE_IDX', 'SYSTEM.CATALOG', 'SYSTEM.CHILD_LINK', 'SYSTEM.FUNCTION', 'SYSTEM.LOG', 'SYSTEM.MUTEX', 'SYSTEM.SEQUENCE', 'SYSTEM.STATS', 'SYSTEM.TASK', 'hbase_auto_demos', 'mytest:videos', 'test']
上述demo列出了当前HBase中的tables。有关于其他增删该查相关的接口方法,请参照示例hbase_thrift_demo.py。
Happybase
Happybase是一个第三方的HBase连接库,对hbase-thrift的一些接口进行了重新封装,接口易用性大幅提升。官方文档参考:https://happybase.readthedocs.io/en/latest/index.html
pip install happybase
happybase库的接口更接近于HBase的API,因此也更容易理解。官方文档里的内容在此不再重复。初学时重点了解connection/row/scan/put/delete/cells方法,进一步了解Batch/ConnectionPool相关方法。
示例中重点讲解了如何使用ConnectionPool获得HBase连接,并检索和修改数据库数据。
Phoenix
Phoenix是一个开源的HBASE SQL层。它不仅可以使用标准的JDBC API替代HBASE client API创建表,插入和查询HBASE,也支持二级索引、事务处理以及多种SQL层优化。
Phonenix具有以下特性:
- 二级索引支持(global index + local index)
- 编译SQL成为原生HBASE的可并行执行的scan
- 在数据层完成计算,server端的coprocessor执行聚合
- 下推where过滤条件到server端的scan filter上
- 利用统计信息优化、选择查询计划(5.x版本将支持CBO)
- skip scan功能提高扫描速度
- 支持Spark、Flink等数据分析框架
为什么使用Phoenix
- 要通过HBase建立数据分析,本身也要建立对搜索字段的维度索引,数据处理过程和使用Phoenix相差不大;
- Phoenix通过SQL语句的编译使得代码兼容性更好,能够支持标准JDBC接口,易于扩展;
- 数据分析的场景使用SQL语句更方便。
如何使用Phoenix
可以通过两种方式使用Phoenix:
-
使用Phoenix Shell 阿里云提供了其Phoenix Server端对应的Phoenix Client,可以结合阿里云帮助文档,使用Phoenix Shell。
-
使用JDBC接口 对于Python可以使用phoenixdb库,对数据进行访问,官方文档为:https://python-phoenixdb.readthedocs.io/en/latest/
有关于Phoenix的使用demo和表结构设计,参见另外一个文档。
Python轻量级Web框架-Flask
附件
附件A:VPN连接和配置说明
在本实例的阿里云环境中,ECS的网段为10.1.0.0/16。我们在测试环境搭建了一个VPN服务,连接方式为L2TP/IPSec,请向管理员索要账号密码。
连接VPN后,将获得一个192.168.42.0/24网段的IP地址。由于需要访问10.1.0.0/16网段,因此需要进行路由配置。
MAC OSX环境下的路由配置
可通过以下两条命令来创建路由。
netstat -nr # 查看路由表,注意看上方IPv4路由表部分的配置
sudo route add 10.1.0.0/16 192.168.42.1
上述命令配置10.1.0.0网段(子网编码:255.255.0.0),都通过192.168.42.1网关进行路由。请根据VPN连接后的实际分配的IP地址,调整网关IP。
注意:VPN连接中断后会导致路由失效,再次连接需重新配置。
附件B:搭建Python virtualenv开发环境
使用virtualenv可以确保项目的Python执行环境符合项目的需要,能够保证第三方模块的版本一致性,而不受系统环境或者其他项目需要的影响。
搭建virtualenv时,我们假设已经安装好pip,如果尚未准备好,可以参照pip的说明文档 预先安装。
首先通过pip安装virtualenv
pip install virtualenv
随后,进入项目目录(通常在项目中创建),并创建virtualenv
cd ~/myapp
virtualenv venv
created virtual environment CPython3.7.5.final.0-64 in 344ms
creator CPython3Posix(dest=/home/dev/python/myapp/venv, clear=False, global=False)
seeder FromAppData(download=False, pip=bundle, setuptools=bundle, wheel=bundle, via=copy, app_data_dir=/home/dev/.local/share/virtualenv)
added seed packages: pip==20.1.1, setuptools==49.2.0, wheel==0.34.2
activators BashActivator,CShellActivator,FishActivator,PowerShellActivator,PythonActivator,XonshActivator
激活virtualenv
source venv/bin/activate
激活后会进入如下界面:
(venv)username@host:~/myapp$
表示当前正在virtualenv环境中,在此环境中的python执行程序再venv/bin中,使用pip安装的库文件在venv/lib/python3.7/site-packages/中。
可以使用deactivate命令,退出virtualenv环境
(venv)username@host:~/myapp$ deactivate
附件C:修改pip的数据源
由于国外的数据源下载速度较慢,建议使用阿里云的pip数据镜像。当然,也可以使用其他源镜像,本文以阿里云为例。
在用户目录中创建.pip文件夹,并编辑pip.conf文件
mkdir ~/.pip
vi pip.conf
在pip.conf中加入阿里云数据源
[global]
index-url = http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com